

A farewell to AI confusion
The most used and least understood word in our technological culture needs some introduction
Have you ever felt overwhelmed by the topic of Artificial Intelligence (AI)? Its vast terminology? Are you using the wrong terms when talking about AI? Ever suspected that a lot of other people are also using the wrong terms?
If your answer is in the affirmative, you should not feel left out. AI is probably the most popular term in today’s technological agenda and, as is common with popular terms, it is enveloped in a haze of ambiguity. From the friendly digital assistant on your phone to genomics research in the lab, its practical value has already been confirmed by an abundance of useful and interesting applications. Empowered by deep learning, today’s AI-enabled systems possess a variety of ways to interact with their surroundings:
1. Natural Language Processing is used by virtual assistants and chatbots to analyze and respond to human voice and written text
2. Computer vision enables the analysis of large repositories of images by advanced image classification systems such as Google Photos, as well as the interaction of autonomous vehicles and robot assistants with their environment in real-time.
3. The field of human-robot interaction studies and designs solutions for the interaction between us and AI, in the form of sophisticated inspired brain-computer interfaces or robots equipped with physical parts.
But have you ever suspected that experts, including researchers, job recruiters and AI practitioners, to date disagree on many AI-related questions? [Spoiler alert: they do.] The reasons behind these disagreements go back to the history and heart of the field of artificial intelligence, and probably explain why so many people find it a confusing topic of discussion. To understand the details, we need to first take a step back….
A very brief history of Artificial Intelligence
Although AI applications flourished quite recently, solely observing the latest trends in machine learning will give us an incomplete picture, and a partial understanding of this science. In order to comprehend how contemporary computers “think,” we need to look a bit deeper into the history of human-machine relationship.
Our ability to imagine artificial life predates our ability to create it by thousands of years. Ancient myths, such as Talos, a bronze man made by Gods to protect the island of Crete, indicate that the concept of robots has long inspired, and often terrified, humans.
But before we move to the realization of these ideas, our experience with our own, human intellect probably urges us to ask: if machines are indeed thinking, what kind of language are they using?
Mathematics had long been the language of formulating logic, but in the 20th century things got serious. Human languages were deemed incomplete and confusing, and mathematicians and philosophers, such as David Hilbert and Bernard Russell, believed that in order to account for all rational, human thought, a language based on mathematics was necessary.
It wasn’t until the 20th century and the appearance of Alan Turing in the scenery of mathematical logic, that the search for this language was translated to the creation of a theoretical machine capable of solving any logical problem it is presented with. This signified the birth of the field of computer science, a branch of which is today’s AI. Built upon firm mathematical foundations, that have been occasionally shaken, AI continues to flourish, often deviating from its pure mathematical origins to more applied approaches.
“Artificial Intelligence” was born, as a term and a science, at the Dartmouth workshop in 1956. In a seminal paper, the founding fathers of AI defined it as the pursuit of making machines as intelligent as us: to “use language, form abstractions and concepts, solve kinds of problems now reserved for humans and improve themselves.”

The industry and academia were initially excited about this promising technology. However, the underestimation of the difficulties involved with AI practice, led to unrealistic expectations. For example, one of the founders, Marvin Minksy of MIT, along with Seymour Papert, assigned to some undergrads a “Summer Vision Project” in 1966, which aimed at connecting a camera to a computer, which would be capable of recognizing patterns, and even identifying objects in a scene. 56 years later, we still have a long way to go. This disparity between possibility and reality sometimes led to disappointment and periods of severe cuts in funding for AI research, which we in retrospect call “AI winters”.
Today, AI is flourishing, but there are still significant limitations that scientists need to overcome. Primary examples of these limitations can be encountered when AI is interacting with the physical world, as robots are embarrassingly bad at simple tasks, such as opening doors. Although we can only judge the AI zeitgeist in retrospect, the recent recipience of the Turing award by 3 prominent AI researchers reveals that the scientific society considers AI a mature, established branch of computer science.

What we can mean by “AI”
Today, the definition of AI has branched into two related, yet significantly distinct concepts. “Strong AI” is more of a philosophical and ongoing pursuit of creating machines with consciousness. “Weak AI” on the other hand, represents a more practical approach, where computer programs are made to perform well at a task believed to require intelligence without being guided by humans.
Although we can say that weak AI has been achieved by today’s machine learning applications, it is still hard to argue whether we have so far created AI in the strong sense. This is because of a phenomenon called the “AI effect”: when we assign to a machine a task that requires thinking, such as playing chess, and the machine manages to solve it, we remove any magical aura that previously enveloped the task and thereafter regard it as simple mechanics. Rodney Brooks, the former director of MIT’s Artificial Intelligence Laboratory says “Every time we figure out a piece of it, it stops being magical; we say, ‘Oh, that’s just a computation.’” Or as Larry Tesler, who worked at the Stanford Artificial Intelligence Laboratory as well as Xerox PARC, Apple, and Amazon said: “Intelligence is whatever machines haven’t done yet.”

Is there a difference between machine learning and just… statistics?
This could be a controversial question, as one can observe in online question-answering platforms, where “battles” take place over the definition and content of the young and ever-expanding field of machine learning (ML). Statisticians often characterize ML as glorified statistics, while ML practitioners call statistics an out-of-date science of impracticalities. The truth is, as usually, somewhere in the middle.
Machine learning has been built on and is to date using many tools from statistics. This is natural, as the objective of ML is to analyze large amounts of data, derive their statistical properties and, thus, learn how to solve similar problems in the future.
Nevertheless, machine learning research has become more specialized, as the problem of teaching a machine how to solve problems differs from classical statistical problems in many regards. While statistics usually solve theoretical problems under unrealistic assumptions, machine learning lays focus on the application. Therefore, aspects such as computational complexity, the finite size of available data and techniques for increased efficiency in execution time, such as parallelization through the use of Graphical Processing Units and specialized software libraries, are the cornerstones of today’s machine learning research.
When did machine learning get deep and why?
The transition from machine learning to deep learning occurred in 2006, as the Holy Bible of deep learning reports. Although the term deep learning was used as back as the 40s, the immense research interest and industrial applications commenced quite recently; and the revolution is still unravelling.
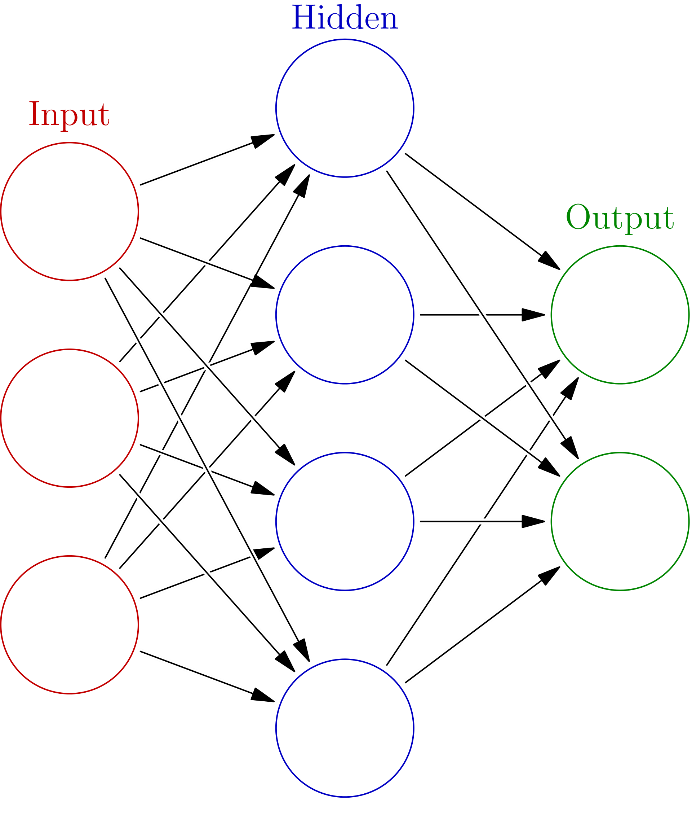
Machine learning uses a variety of mathematical models to perform the learning task, but in deep learning, Artificial Neural Networks (ANNs) are the main model of use. The reason why we today call these models deep is that they can solve difficult problems by having different levels of understanding that gradually lead to a deeper understanding of the involved concepts.
In the past, data scientists had to put immense effort into processing their data before they presented it to the program, but contemporary AI systems can work with real life data. Virtual assistants can understand your voice, autonomous cars can observe their environment and quickly respond to accidents, while Google Translate can do a surprisingly good job with your texts, all thanks to applied deep learning.
Artificial Neural Networks and cats
Being at the core of every deep learning system, ANNs are worth a closer look when trying to understand the internal workings of AI. Although their structure was inspired from biological neural networks, it may be a bit misleading to think of them as an artificial brain.
ANNs incarnate the long-standing AI idea of connectionism: that it’s possible to simulate advanced intelligent behavior only by using a large number of simple computational units. These units are called artificial neurons and can be seen as a simple neuron that accepts an input and performs a mathematical operation on it to give an output. When we connect neurons to each other, we form the neural network. This is usually organized in layers, that are placed one after the other, so that the input of the previous layer is the output of the one following it.
As such, we can see an ANN as a complex mathematical model that has the form of a graph. AI research has long lost its connection to neurobiology and current successes are not so much because of advances in our understanding of the human brain, but due to hardware acceleration or computer science discoveries. Nevertheless, despite its simple structure and operations, an ANN can today look at pictures, find all the cats in them and, even generate pictures of cats that it has never seen before.
This is not black magic, it is what we call deep learning. The main idea is that we may not be able to understand how a task is solved, but we can break it into simple steps and gradually get the broader picture. When we analyze a picture, we think differently from machines. Where we see objects and colors, machines only perceive two-dimensional arrays of pixel values that quantify the intensity of light at different parts of the picture. In applications that require computer vision, the AI field concerned with understanding visual information, deep learning has not just brought improvement, but served as an enabler.
As early as the 50s, biological experiments had revealed that neurons in the animal brain react to simple geometrical patterns. Today’s application of deep learning confirms this principle: a deep ANN uses its first layer to detect dots and lines, its next layers to locate more complex geometrical shapes and the deeper layers to categorize these shapes into concepts, such as cats. By training the network on millions of pictures with different labels, the network can learn the concept of a cat, which it can then use to produce its own, sometimes strange, cat pictures.

Image credit: ajolicoeur.wordpress.com
It’s a data-eat-data world
Despite the immense advancements in AI techniques, software libraries and hardware, there is a parameter in every AI project that is hard to control: data. The deeper the employed networks, the more data are necessary to ensure that learning has correctly recognized the statistical properties of the problem.
As data are usually generated by the online behavior of users, such as their presence in social media and their personal pictures uploaded to the cloud, it is easy to imagine why technological behemoths such as Amazon, Google and IBM, have launched a variety of products that offer personalized user experiences. The unceasing growth of these companies can be explained by a phenomenon market specialists call the success cycle: the more data available to a company, the better the AI services the company offers, which results in users being more willing to use these services and, thus, generate more data that the company can leverage to improve its services.
Being a vast and heavily popular area, AI naturally gives birth to a number of misunderstandings. This in turn can create a feeling of uneasiness, even fear, in front of its power and the effect it can have on our society, which can explain statements such as Stephen Hawking’s prophetic remark that “the development of full artificial intelligence could spell the end of the human race”. While Hawking was talking about strong AI, Steve Jobs preferred to approach technology in a more applied, human-oriented attitude, by saying that “computers are bicycles for the human mind”.
While choosing one’s position is hard, one thing is certain: AI is a technology that will, and already is, changing our society. As with all social phenomena, developing a responsible attitude towards AI requires us to look beneath the haze of confusion and gain an overall understanding of the “whys” and “hows” of this exciting field.
 Future Tech Review #6: Artificial intelligence is the new horsepower
Future Tech Review #6: Artificial intelligence is the new horsepower 