

AI & Embedded Vision — Driving System Innovation
Digital image processing has dramatically altered our ability to see our world—and the world beyond—in two dimensions.
Digital image processing has dramatically altered our ability to see our world—and the world beyond—in two dimensions. Initially requiring vast amounts of computing power for low-resolution images, new developments in digital image processing gave us our first images of the moon in the 1960’s, transforming our perception of Earth’s natural satellite. Later advancements in traditional digital image processing brought us technologies on which we’ve come to rely, from medical visualization technologies such as to machine vision systems on the factory floor. Despite the innovations it’s engendered, traditional digital image processing can only take us so far. Rather, it’s the application of artificial intelligence (AI) and more sophisticated embedded vision technologies that are driving digital system image processing to a whole new level.
What are the advantages of AI over traditional image processing—and how can you use it without being an AI expert? And what are the current and future uses of AI and embedded vision? This article will explore these questions in greater depth.
AI vs. traditional image processing
If all image processing were conducted in a controlled environment, such as interior spaces with uniform lighting, shapes, and colors, we’d have little need for AI. But this is seldom the case because most image processing takes place in the real world—in uncontrolled environments such as streetscapes or in industrial settings in which objects of different shapes and colors are the norm, not the exception.
AI tolerates significant variation in ambient lighting, viewing angle, rain, dust, occlusion, and other environmental factors, so if you’re capturing cars moving on a street during a 24-hour period, your lighting and image-capture angles are constantly changing.
As another example, let’s imagine you’re a large tomato grower and you need to package tomatoes in three-packs for distribution to grocery-store warehouses. The tomatoes must be uniform in shape and color to meet the quality-control standards of your warehouse customer. Only an AI-based imaging system can support high variation in shape and color, to identify only those tomatoes that are round and red.
It sounds good, but if you’re neither an expert in AI or in image processing, how do you meet this goal?
Go GUI to train neural networks on 2D objects
It’s been years, not decades, since AI tools with a graphical user interface (GUI) have become available for training neural networks on 2D images. Prior to this monumental achievement, training neural networks for machine vision and inspection, or for smart transportation platforms, would have required extensive expertise in AI/machine learning and data science, a costly and time-consuming investment for any company. Fortunately, as times have changed, AI tools have changed with them.
What should you look for in a GUI tool for AI?
- Make it flexible—find a GUI tool that lets you bring in your own image samples and train neural networks to perform classification, object detection, segmentation, and noise reduction, so you can reap the benefits of greater flexibility and customization
- Keep it local—use a tool that lets you model your training data on your own PC without connecting to the cloud, giving you the higher level of data privacy now required by many industries
- Export for inferencing—choose a tool that lets you export your model files to an inference tool, so you can execute on live video stream
- Get intuitive—visualize model performance with numerical metrics and heatmaps
- Tap into pre-trained models—reduce your training effort by using the pre-trained models that come with your software package
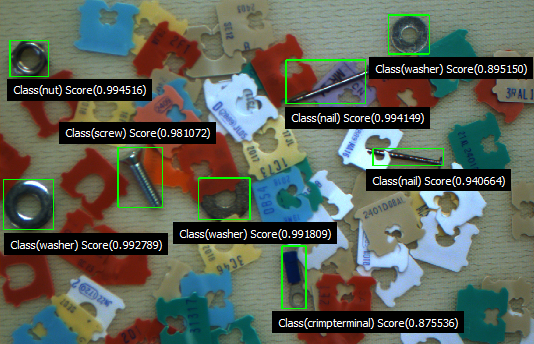
Let’s consider an example. You need to locate and identify specific hardware parts, nuts, screws, nails, and washers, but those parts are crowded on a reflective surface with a host of colorful tags. Achieving the high robustness required would be extremely time-consuming using traditional image processing, but an AI tool can provide an object-detection algorithm that’s easily trainable using just a few tens of samples. This type of software tool will allow you to more quickly and easily build a robust and accurate location-and-detection system, reducing human development time and its associated costs.

Intelligent transportation systems (ITS) are also well-matched to AI image processing systems. From toll management and traffic safety monitoring to speed and red-light enforcement, AI software can be used to locate, segment, and identify vehicles and other moving and stationary objects with high accuracy.
Follow the steps
Once you have your AI software tool in hand, there are a few major steps in your development process. First, you’ll need to create your data, then edit and modify your data set. You’ll start by acquiring training images and providing annotations that correspond to those images. Generally, you’ll import these images from folders in remote locations or obtain them from a network or folder on a PC. As you engage in this process, remember that the quality of your model is predicated upon the quality of the data sets in your model. You’ll also need to select a graphics processing unit (GPU) with sufficient power to manage your image processing.
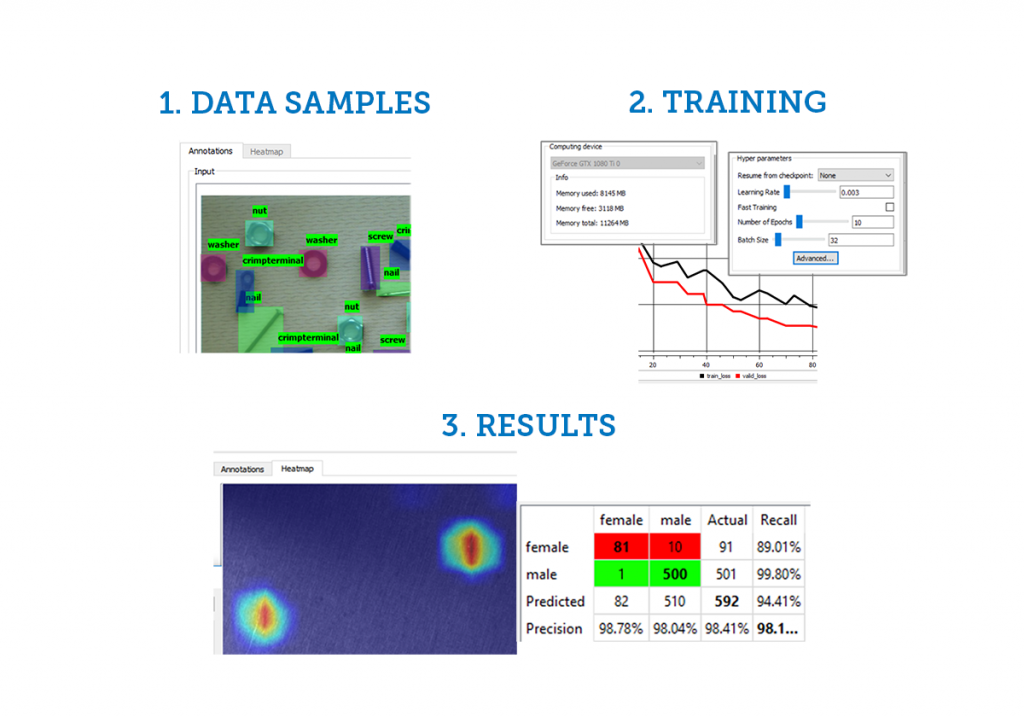
Next, you’ll pass the data through a training engine to create your model.
Then, you’ll need to conduct model-testing using your results. This includes using a confusion matrix to show false positives and false negatives to visualizing a heat map that shows the activation of your neural network. Now that your model is trained and tested, it’s ready to be exported to a model file for use on an imaging processing application.
Plug and play with embedded vision
As a topic, embedded vision bridges many different interpretations. Variations are available, including embedded vision platforms with built-in AI, and each user should weigh the options (including cost), before making a decision.
Embedded vision may include a camera with an embedded processor or field programmable gate array (FPGA), a programmable vision sensor or smart camera, or a general- purpose machine with a flexible embedded application. However it’s deployed, embedded vision applications are known for their small footprint, encompassing reduced size, weight and power (SWAP).
Embedded vision applications also enable data reduction from the camera to a host PC, reducing the volume of data going through the pipes. And there are other benefits, including reduced cost—since embedded vision applications don’t require expensive GPU cards on a PC—as well as predictable performance, offline operation (a network connection isn’t required), and easy setup. If you’re looking for an all-in-one product that’s simple to setup and deploy to the field, embedded vision offers tangible benefits.
Embedded vision is well-matched to industrial applications, such as error proofing and identification. What does this look like in the real world?
Error proofing
- Pattern matching – check presence, position
- Feature or part presence/absence/counting
- Feature or part measurements
- Part or assembly verification by color
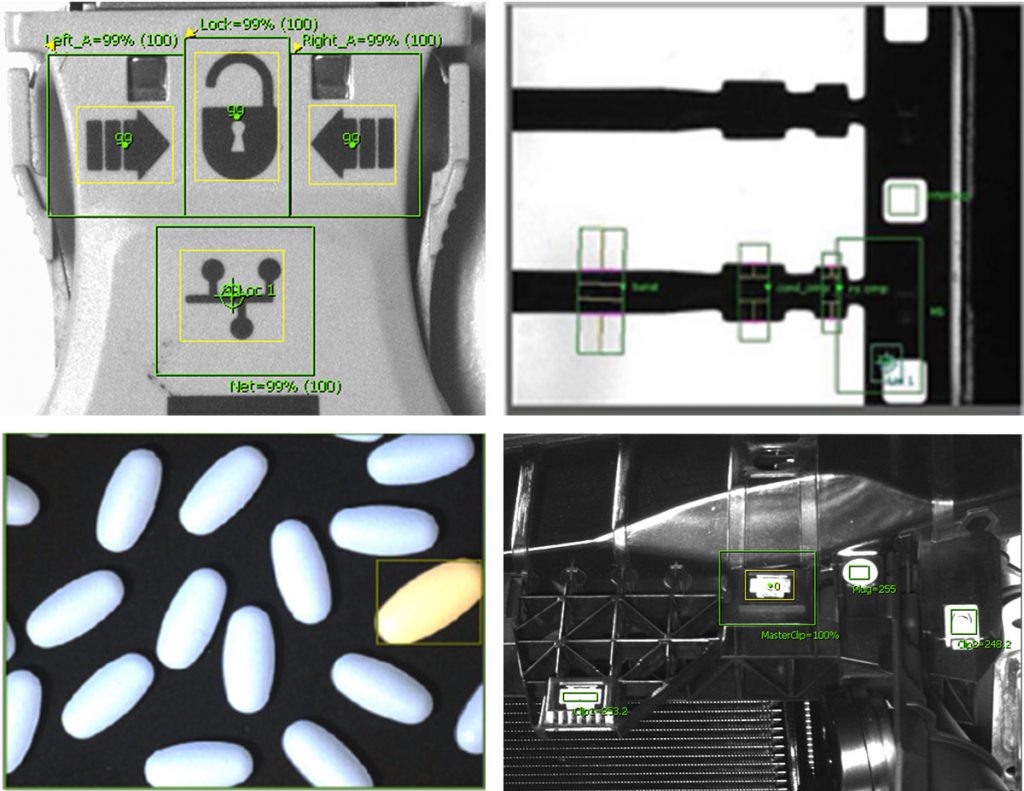
Identification
- Product verification – read product codes to avoid labeling mix-ups
- Marking verification – validate product type, lot, date codes
- Quality verification – check markings, label position, feature presence/absence
- Assembly verification – track assembly history at every stage of manufacturing
- Logistics – ensure proper flow through receipt, picking, sorting, and shipping

Whether used separately or together, AI and embedded vision mark evolutionary leaps in digital image processing. For example, a traffic application that enforces red lights and speed limits uses embedded vision systems to capture images in the most efficient way possible. It then uses AI to help the device perform reliably in varying weather and lighting conditions. Is it raining or snowing? Is the light bright or dark? AI implementations allow the device to adapt to uncontrolled real-world conditions.
Through AI and embedded vision, the next generation of digital image processing technologies can determine if a car has enough passengers for the carpool lane, if drivers are using cell phones in cars, or if the driver and passenger are wearing seat belts. That’s a level of intelligence that can enable more thoughtful drivers as well as safer transportation by car.
While advances in sensing, processing, and software technologies—as well as in smart cameras—are largely responsible for the progress we’ve made in AI image processing and embedded vision systems, we must also credit the rise of edge AI. Edge AI reduces costs and bandwidth—because high volumes of data aren’t continuously sent off to the cloud for processing—as well as latency, promoting greater privacy and speeding application performance.

And that’s just the beginning of what we can accomplish with these newer image processing technologies. Once we’re able to bring “continuous learning” to machines in the field, we’ll have devices that learn automatically at runtime. By adapting an existing model to a context shift, continuous learning frees the development team from performing a mandatory full model re-training in the lab, saving countless human hours. A good example of this approach is a drone flying at multiple altitudes for traffic surveillance. We can train the initial model with images collected at one single altitude, e.g., 10m. Once deployed in the field, the continuous learning algorithm kicks in, “adapting” the model when the drone is flying at other altitudes.
Without continuous learning, we’d have to retrain the model for each altitude reached by the drone to achieve accurate performance. But with it, the model responds to variation in size and distance as well as the viewing angle of the vehicles. This type of on-the-go learning in image processing technologies dramatically improves application functionality.
Interested in learning more about AI and embedded vision solutions? Watch this informative webinar by Bruno Menard, Software Director, Teledyne DALSA.
 A farewell to AI confusion
A farewell to AI confusion  AI and medical imaging: building a relationship on solid data foundations
AI and medical imaging: building a relationship on solid data foundations 