

Bob’s Imaging Fundamentals #9: Machine Vision Techniques Part 2
Blobs. What are they good for? Aside from being great practical jokes at parties, blobs have some interesting properties for Machine Vision, but I am getting ahead of myself. You may recall from our previous discussion on creating blobs, that I said a blob consisted of a list of pixels. Some of you may have wondered “How do you make a list of pixels? They’re just a bunch of dots!?!” Well, that is a very good observation. In fact, what I neglected to mention in that article was that each pixel in an image has its own set of coordinates (kind of like an address). Let’s take this picture of my car as an example – it’s been thresholded of course:
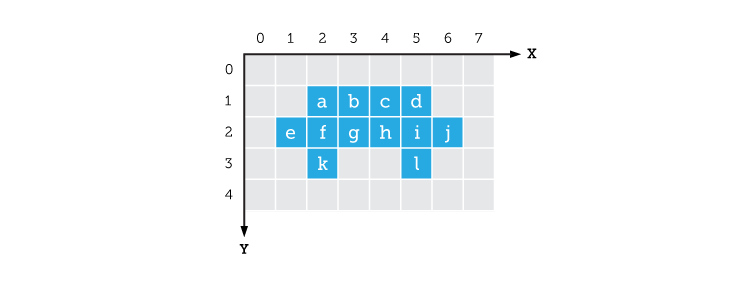
If we make a list of the positions of all the blue pixels, we will have described the blob that is my car:
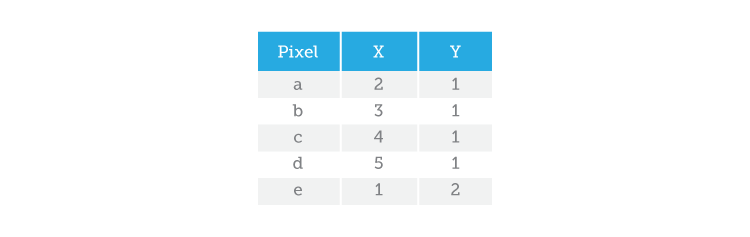
Now comes the fun part! Once you have the coordinates of all the pixels in a blob, you can use those coordinates to figure out some of that blob’s global characteristics. Obviously, you will not be able to tell whether my car needs washing because we have thresholded the original image and lost all the grey level information (for dirt detection we would use an approach without thresholding). By using the list of coordinates, you could determine the object’s size and general shape (thin, fat, round, square). Or, if you already had a list of coordinates describing an object of particular interest, you could try to match each blob in your image to the object you are trying to find. To do that, you would compare the list of coordinates of your ‘search’ object to the list of coordinates of every blob in our image. In Machine Vision, this technique known as Template Matching, is key to helping us locate known objects that will ultimately guide further processing steps. But that, I will leave for a future article.
Basic Compression
Basic Compression – the act of reducing the amount of data required to represent an image. When I first explained how to build a blob from a bunch of thresholded pixels, I’m sure I heard some of you yelling, “What about Run-Length Encoding!?!”. Well, I couldn’t really talk about RLE without first explaining things like pixels and their coordinates. So, let’s go back to the picture of my car:
We’ve already created a blob with my car by listing all the pixel coordinates that make up the blob. So how much information does that make? Let’s see, 12 pixels with two coordinates each (x, y) that makes 12 x 2 = 24 numbers (or, bytes). Now let’s try to describe my car using Run-Length Encoding. To do that, we go through each line in search of a valid pixel (in this case a blue pixel). Once we have found one, we take note of its position and count how many valid pixels come after it. So, with RLE we can describe the same blob like this:
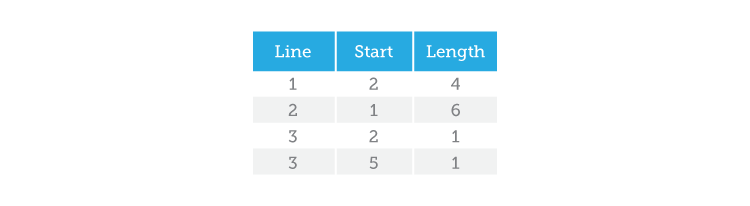
There you have it! We have gone from 24 bytes (using pixel coordinates) to only 12 bytes with Run-Length Encoding. As you might imagine, RLE is a very popular method of data description for blob analysis because it uses less space to describe your object. This proves to be a major advantage when a camera produces big images (many pixels) at a fast rate (high bandwidth) because it allows us to process less data, which translates to getting results faster!
Stay tuned for more Imaging Fundamentals with Bob!
About this article: Bob’s Imaging Fundamentals is an article series based on the work of Bob Howison. Originally titled Bob’s Brain Snacks, these articles were intended to help employees and partners get up to speed with the fundamental concepts of image processing. They became such a popular reference that we’ve decided to bring them to the Possibility Hub. As technology goes further, faster, and new industries discover the power of digital imaging, it’s important to remember the basics.
Bob’s Brain Snacks are recommended for anyone interested in learning about imaging technology. Sharpen your mind and try one!
 Bob’s Imaging Fundamentals #7: Flat Field Correction – Not just for farmers anymore
Bob’s Imaging Fundamentals #7: Flat Field Correction – Not just for farmers anymore 