

Bob’s Imaging Fundamentals #15: Basic Compression
The act of reducing the amount of data required to represent an image
When I first explained how to build a blob from a bunch of thresholded pixels, I’m sure I heard some of you yelling, “What about Run-Length-Encoding!?!”. Well, I couldn’t really talk about RLE without first explaining things like pixels and their coordinates. So, let’s go back to the picture of my car:
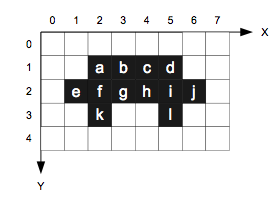
You may remember that we created a blob with my car by listing all the pixel coordinates that make up the blob. So how much information does that make? Let’s see, 12 pixels with two coordinates each (x, y) that makes 12 x 2 = 24 numbers (or, bytes). Now let’s try to describe my car using Run-Length-Encoding. To do that, we go through each line in search of a valid pixel (in this case a black pixel). Once we have found one, we take note of its position and count how many valid pixels come after it. So, with RLE we can describe the same blob like this:

There you have it! We have gone from 24 bytes (using pixel coordinates) to only 12 bytes with Run-Length-Encoding. As you might imagine, RLE is a very popular method of data description for blob analysis because it uses less space to describe your object. This effect of compression is a major advantage when a client has a camera that produces large images (many pixels) at a fast rate (high bandwidth), it allows us to process less data which translates into getting your results much faster.
