

Human and Machine Pattern Recognition
To survive we must recognize visual patterns that indicate food, danger, mates, etc. Our visual pattern recognition is based on innate (“built in”) knowledge and lots of learning. For example, a newborn favors looking at well-formed face patterns and quickly learns to discriminate mother’s face from others.
The equivalent to innate knowledge in a machine vision system is software for feature detection. Feature detectors recognize pattern components, such as edges and corners. You can combine features to recognize more complex patterns, such as surface defects on parts. The time and skill required to program pattern recognition using simple features has been reduced by innovations in graphical user interfaces and making feature detectors smarter. As an example, a “caliper tool” improves reliability and ease-of-use by adding knowledge that you are measuring two, parallel edges.
The equivalent to learning in a machine vision system is software that you can teach to classify (recognize) a type of pattern, such as recognizing a part’s color patterns. These capabilities are examples of machine learning. Modern machine vision software, example, Teledyne DALSA iNspect vision systems, provide feature detectors, tools, and trainable classifiers.
We will discuss some aspects of machine learning, as applied to machine vision. First, we ask what a pattern is and give an example of how human visual pattern recognition can motivate machine vision pattern recognition algorithms.
What is a Pattern?
We know a pattern when we see it but can’t give an exact definition, as patterns are based on individual learning, innate knowledge, and context. The left and right sides of Figure 1 have different densities of random dots. There is no pattern on either side but, where they join, we recognize an “edge”. This “edge” exists only in the context of these two noise patterns.

Saying that patterns contain “information” might help in theory, but information still is based on knowledge and context.
Human Pattern Recognition Example
In human vision, elemental features, such as edges and colors, are detected and assembled into more complex features. Thus four appropriately placed corners signal a rectangle. To recognize a rectangle, a machine vision system detects corner features, knows the geometry of rectangles, and requires limits on how the rectangle is presented.
Complex features are, somehow, assembled into perceptions based on our understanding of the visual world. For example, in Figure 2, we interpret broken lines as outlines of a closed circle and a closed rectangle. In the world, object edges are often interrupted by other objects and our visual system uses that knowledge to complete or close object outlines.

We want machine vision systems to have similar capabilities but we might not know how to do this for unconstrained imaging situations, such as autonomous vehicle navigation. Machine vision systems use constrained imaging situations for high speed and low cost. The classic “bin of parts” problem – picking a part, such as a water pump, from a bin – is an example of a constrained imaging situation, in that we know the shape of the pump and could use 3D imaging to discover how one pump’s shape obstructs another’s.
Machine Learning
Using machine learning, a vision system learns what combination of features delivers reliable pattern recognition. Automated learning is usually less effort than programming a solution using features.
In Figure 3, the middle row shows types of machine learning and the bottom row has result types. In supervised learning, you train the vision system by “showing” it examples of the patterns you want to recognize and “telling” it what pattern it is looking at.
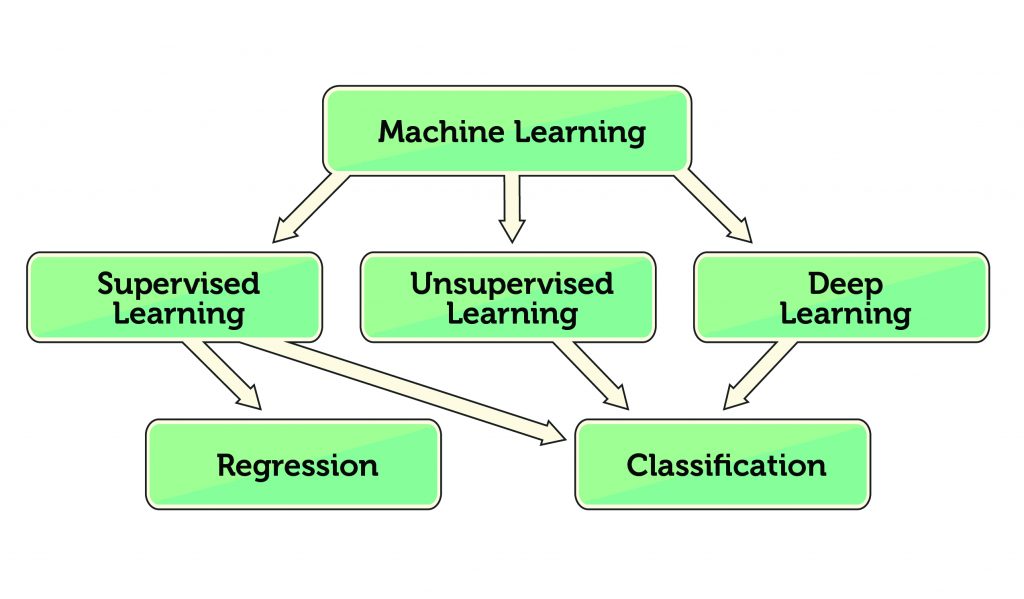
In unsupervised learning, the vision system is only “shown” examples, and groups (clusters) the examples’ features with minimum error. This is useful for discovering “natural” classes for the input feature data and is sometimes used to set up supervised learning.
In both cases, you first select feature detectors that you think will “capture” the defining aspects of the pattern. This can take skill and, of course, limits the machine learning to your selected features. Suppose you are not sure what features to select for machine learning? Deep learning is a form of supervised learning that learns both features and pattern recognition.
Once trained, pattern recognition is called regression if the results are continuous and classification if the machine’s “answers” fall into discrete classes. An example of regression is the predicted probability of part failure based on the extent of visible cracks. That part might also be classified as “good” or “bad” by a limit (threshold) on the extent of visible cracks.
ANNs and Deep Learning
A common implementation of machine learning uses artificial neural nets (ANNs), loosely modeled on networks of biological neurons. Each “neuron” in an ANN weights and sums input signals (features) and applies a function to this sum. The weights that multiply the input signals are adjusted to learn the desired input patterns. Pattern recognition is indicated when the function output is greater than some threshold.
Deep learning has only recently become practical because it needs large, labeled data sets (“big data”) and massive amounts of computer power for training. ANNs usually have three layers of artificial neurons but a deep learning network might have a hundred or more layers. The increase in layers allows learning complex and abstract features that make better classifications.
Because deep learning learns from pixels, expert skill is not required to select appropriate features for a pattern recognition task. Some of the complex features learned look unlike what an expert would select as “good” visual features. As in the brain, abstract features no longer resemble the elements they were derived from. And, as in the brain, learned knowledge is distributed across artificial neurons, making it difficult to say exactly what complex features have been learned.
Deep learning is attractive but here are three problems in using it to do machine vision pattern recognition. First, big data sets are needed for training. In most machine vision applications we have very few examples of defective parts to use for training. After all, a factory is not designed to produce defects!
Second, the massive computer power needed for deep learning is still an impediment. Often the deep learning is done in “the cloud” (rented, networked computers) and downloaded to run in the vision system.
Third, the reliability of deep learning systems is not at the level required by many manufacturers. Because of the complex, distributed features in deep learning neurons and the number of neurons, it is very difficult to understand what the network is doing and so be able to improve reliability or know when it will fail.
Color Pattern Recognition Example
Suppose you want to recognize (classify) red and green apples. Figure 4, left, shows a color space of all red and green pixel intensities. Each pixel in the input image maps to a point in this color space. Example mappings for three points on red and green apples are shown by red and green arrows.

You supply labeled images of red and green apples, and the training adjusts a supervised classifier’s parameters so it reports “red” when a red apple is seen, “green” when a green apple is seen. You only need to label pixels from red and green apples and let the classifier compute until it converges on a reliable classification. Sounds easy but, there are issues…
It would take you a long time to label every combination of red and green intensity, and a very long time if you add a blue component. So, in practice, the classifier generalizes from a few color examples to give a representation of red and green apple colors. In Figure 4, the two ellipses show the representations of red and green colors, generalized from a few color samples. Any generalization means going beyond your data and so has risks of mis-classification.
Second, representations of colors often overlap. Making the best decision as to an input color’s class in overlapping class areas is a major research topic. Third, as shown, shading and natural color variations add “noise” to the classification. This makes unconstrained color classification very challenging. For machine vision, manufactured parts have much lower color variation, little color space overlap and we control the illumination to provide much more reliable classifications.
The Tip of the Iceberg
The fields of machine pattern recognition and automated classification are deep and older than either of us. I hope this introduction gave you some basic ideas and terms. Key points are the differences between innate and learned knowledge, features and “higher order” combinations of features, machine vision taking hints from human vision, and the implementation of machine pattern recognition using machine learning and, in particular, artificial neural nets.
When you relax in your self-driving car, ponder how reliable are the neural nets that are driving you and, to be fair, how reliable your neural nets are while driving.
