

Future Tech Review #8: Computer vision goes mainstream
One way to evaluate a technology's advancement is by how many people can use it
As machine learning continues to advance computer vision, we expect we might also see tangible benefits in society. Processing becomes faster, and devices and computers become capable of handling much more information, more quickly, and with a finer level of detail. They also often become easier to use. This allows us to explore new, and perhaps what may have historically been considered impractical solutions. At the same time, it also brings new participants to the party, with a host of different needs, perspectives, and ideas. In this edition of Future Tech Review, we look at five recent examples of what more powerful and accessible computer vision can do to help us experience, understand, and potentially save lives.
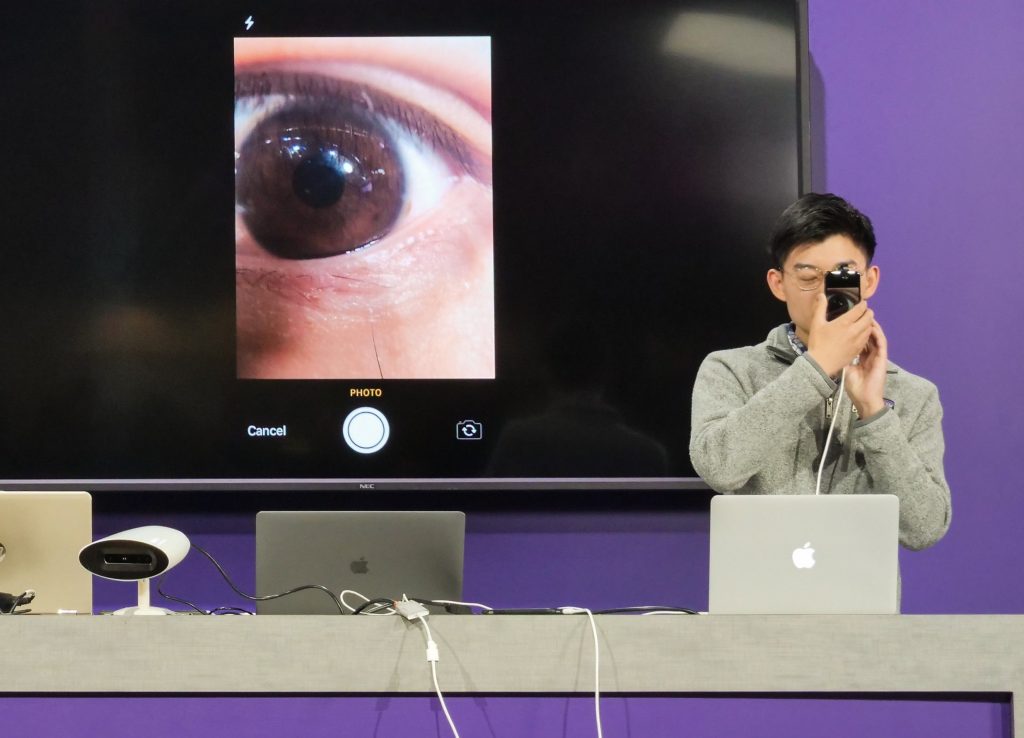
1. Making the world better with computer vision
All three finalists of Microsoft’s 2019 Imagine Cup found ways to use computer vision to create solutions for social good.
- EasyGlucose is a cloud-powered, non-invasive, and cost-effective method of blood glucose monitoring for diabetic patients. A deep learning computer vision framework using convolutional neural networks developed with Azure Virtual Machines analyzes iris morphological variation in an eye image to predict a patient’s blood glucose level.
- Caeli engages your mobile phone camera to create custom anti-pollution and drug delivery masks for asthmatic and chronic respiratory patients.
- Finderr uses a custom camera and computer vision algorithm to track the placement of everyday items for people with visual impairments.
The Imagine Cup aims to empower future innovators with the tools and resources to bring their technology solutions to the world. Registration for 2020 is now open!

2. Reconstructing What Armstrong and Aldrin Saw
One of the most dramatic moments of the Apollo 11 mission occurred when Neil Armstrong changed course to steer the spacecraft to an unplanned location citing the original spot was too dangerous – even though he was low on fuel, had never flown the lander this way in training, and had no time to inform mission control. And because of the placement of windows on the spacecraft, there was no footage of what Armstrong actually saw that made him change course. Today, with some reconstruction, NASA can show us what Neil Armstrong saw more than 50 years ago.
NASA’s team behind the Lunar Reconnaissance Orbiter Camera has been able to reconstruct the last three minutes of the landing trajectory (latitude, longitude, orientation, velocity, altitude) using landmark navigation and altitude call outs from the voice recording. From this trajectory information, and high resolution LROC NAC images and topography, they were able to simulate exactly what Armstrong saw in those final minutes as he guided the lander down to the surface of the Moon.

3. AutoML: The Next Wave of Machine Learning
Deep Learning has enabled remarkable progress over the last few years on a variety of tasks, such as image recognition, speech recognition, and machine translation. Still, neural architectures are mostly developed manually by human experts, which is both time-consuming and error-prone. New interest and progress in Automated Machine Learning (AutoML), the process of automating the end-to-end process of applying machine learning to real-world problems, means that this technology can become more available to more people, including those with no major expertise in the field. Also, Elsken et al survey available automated methods in their paper, as well.
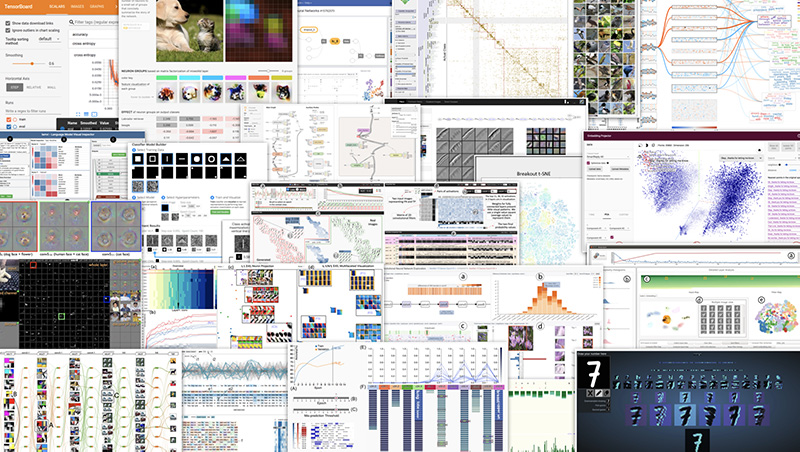
4. Visualizing how Deep Learning is actually doing
Deep learning has made many challenges much easier to solve. While we can see the results, the complex and almost alien logic of how neural networks actually work make it harder for us to understand the results we get, and how to improve them. Here a team at Google tries to alleviate this with an a visual animated representation of what’s going on in a neural network.
Also, in Visualization in Deep Learning, author Fred Hohman reviews multiple approaches to visualization as part of a larger trend towards the “democratization” of AI, where the barriers to understanding, developing and deploying neural networks is lower than ever before.

5. Understanding your Convolution network with Visualizations
While these visualization methods are great learning tools, these examples are biased towards relational neural networks (RNNs) as opposed to convolutional neural networks (CNNs) typically used in computer vision. Also, most of these tools focus on presenting the results as opposed to showing you how the network actually developed its conclusion.
Anki Paliwel’s post sees him using visualization to understand what and how exactly his large model is learning. Looking at different images from convolution layer filters, he believes he can see how different filters in different layers are trying to highlight or activate different parts of the images provided. He also says it becomes clear what different layers are actually trying to learn from the image data provided to them.
Technology is a word that describes something that doesn’t work yet.
– Douglas Adams
The irony of improvements bringing new participants to a technology means that expectations change, too. What’s good enough for research isn’t good enough for the enterprise. What’s good enough for enterprise isn’t good enough for the consumer. It’s almost as if invention and innovation are destined to be driven by a level of dissatisfaction with the status quo…
 Future Tech Review #6: Artificial intelligence is the new horsepower
Future Tech Review #6: Artificial intelligence is the new horsepower 