

Imaging to Perfection
How image processing and deep learning are bringing us closer to perfect products and processes
The sushi box, unconcerned, rides the conveyor line. Beneath it, a sensor weighs its content, while the image processing system, fed by and controlling the camera, examines the texture of the fish and the hue of the seaweed. In the meantime, the AI component, running at the back end, locates the barcode and instructs the barcode scanner to store it in the database. Natural Language Processing algorithms check the printed expiry date and product description. The sushi box has almost made it to the finish line, when the AI algorithm responsible for object recognition detects the absence of chopsticks. Τhe image recognition system labels the box as faulty, and extends a mechanical arm that, sadly, pushes the sushi box onto a second conveyor belt for flawed products…
A completely automated system of sensors and other devices decides the products you see…and those you don’t.
How did everything become so automated?
The list of successful emerging technologies keeps getting longer. Advances made in the areas of artificial intelligence and blockchain, and smart products (from wearables to homes to autonomous cars) are not just stacking up, they are influencing and amplifying each other. The speed and scope of the resulting changes are disrupting everything from how products are made to the legal and cultural frameworks we all live under. This isn’t business as usual; this is a new industrial revolution.
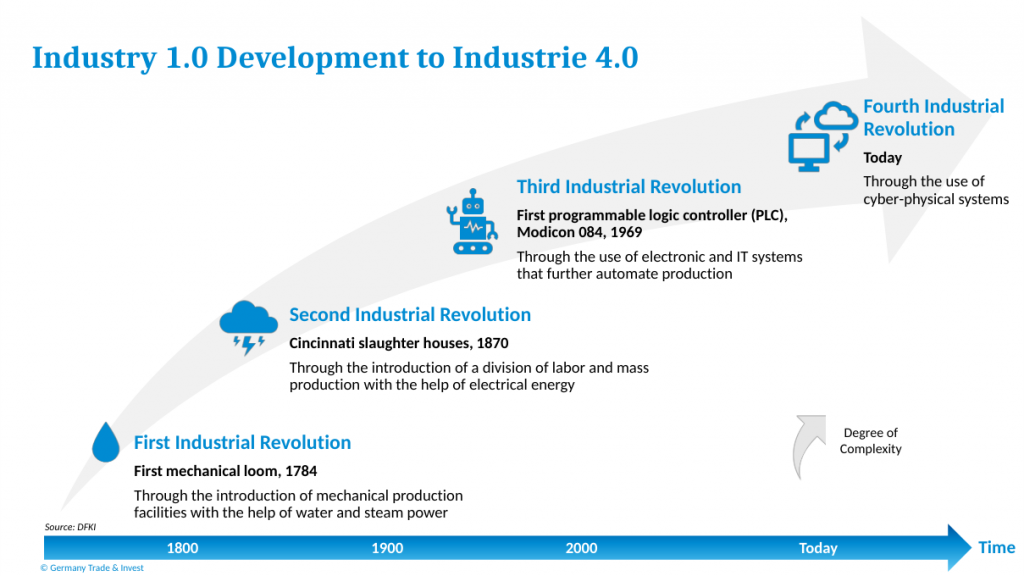
Revolutions of the past can be traced back to the discovery of a specific toolset: mechanical machines that pulled us away from tedious, manual agricultural methods (industrial revolution #1), steam engines that equipped factories (#2) and computers that brought about the information age (#3). But the spirit of this new revolution lies in a more abstract concept: interconnection.
The German government introduced the term Industry 4.0 to describe their vision of this new smart industrial world. The easiest way to visualize this concept is to think of a smart factory, where the physical world seamlessly blends with the digital world through the use of sensors, actuators and advanced communication systems (termed as cyber-physical systems). These devices are essential for gathering and exchanging information, which in its turn is vital for the AI algorithms used to automate industrial processes, such as that of fault detection.
No matter how hard we try to avoid the occurrence of faults during production, they are a statistical reality. Although defect rates are usually low, the stakes are high. In 2016, Samsung released the Samsung Galaxy Note 7, a smart-phone that soon proved prone to overheating. Over 100 cases of flames and explosions were reported, which led to the recall of all 2.5 million devices. Samsung, allegedly driven by the fierce competition among tech companies, performed bad quality control that ultimately led to losses amounting to over $3 Billion, not including the investment required to rebuild its image in the future. Even if faults are kept at low levels, quality seems to have an unbalanced effect on customer satisfaction, amplifying the damage of negative experience: a satisfied customer tells 6 people about a positive experience, while an unsatisfied spills to 14.
Fault detection has evolved alongside the industrial revolutions and the means of applying/exercising quality control have improved in terms of performance, by studying industrial processes and understanding the generation process of faults. But, up until now, fault detection required a human-in-the-loop, to constantly monitor a production process. Since the advent of vision inspection and image processing algorithms, cameras are now able to search for faults within the products, but the list of faults was predefined and, thus, restrictive.
Today, image recognition algorithms, which employ both image processing and deep learning techniques, can “learn” the concept of a flawless product and recognize products that deviate from it in multiple ways. Apart from the apparent advantage of reducing the cost of production by freeing up human resources from the tedious task of monitoring, this level of automation can help the industry achieve something beyond the reach of traditional, human-operated factories: omnipresent and omniscient quality control.
We should not regard this as yet another improvement in the accuracy of quality control. Instead, a complete automation of industrial processes, through a combination of advanced physical systems and image recognition that will help eliminate the parameter that has always introduced uncertainty into the evaluation of all our operations: the human factor. To embrace this possibility, one needs to look into the power of our current technological progress.
What is image recognition?
From an AI perspective, image recognition belongs to the area of pattern recognition and is an example of supervised learning. While image processing refers to a variety of transformations that can take place to convert the image to a format useful for an application, image recognition is the technology concerned with understanding the content of the image. It primarily employs deep learning algorithms, but processing techniques from traditional image analysis are often required. This is because the input to such a system, which consists in pictures, that from a computer perspective are two-dimensional tables containing raw pixel values, often needs pre-processing: Is there noise in the picture? Is color relevant to the task? What is the texture of the objects?
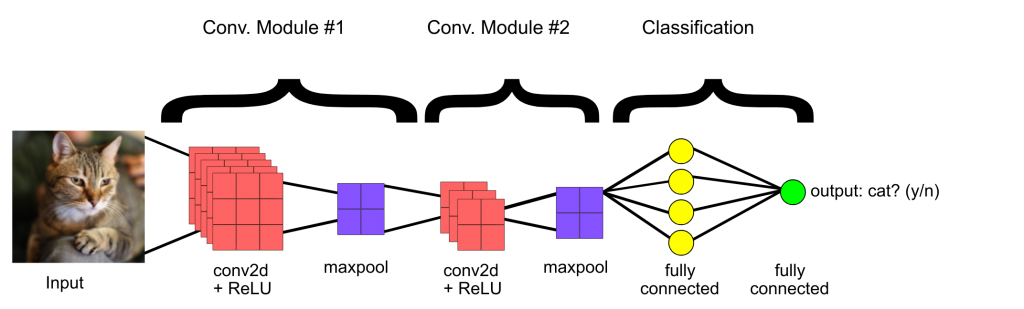
Specifically in fault detection, the learning task is to find the properties of a flawless product by observing many pictures of it, provided by human specialists. This knowledge is referred to as the model, which has the form of an artificial neural network. The described process, termed training, is the computationally intensive part of deep learning and is usually performed offline, requiring time, resources and repositories of millions of images. Subsequently, the model can be easily employed to monitor newly produced products and classify them as flawed or flawless. For image recognition tasks, a specialized type of artificial neural network is used, called a convolutional neural network.
How do convolutional neural networks “see”?
Convolutional neural networks aim at extracting the useful features in an image. They consist of consecutive layers of neurons, with each layer gathering information at a specific level of detail. Simplistically, we can imagine the first layer as seeing pixels, the second seeing lines, the third abstract shapes and the fourth one objects. This convolutional network is followed by another network, termed as a classifier, whose objective is to classify the picture as flawed or flawless based on the features extracted by the previous network.
Although quite similar to classical feedforward networks, this family has the property of translation invariance. This suggests that, if the network has learned the concept of a “chopstick”, it can recognize it regardless of its specific position or angle of it in the picture. Although this ability may sound quite trivial for a human, it was not present in neural networks until recently, making the application of AI in vision-related tasks impossible.
Despite its immense power, deep learning comes with limitations. While deep neural networks can extract features and learn important concepts without requiring human intervention, there is one thing that they today need more than ever: data. This has given a number of headaches to AI experts:
- Data collection is tough, with toughness varying across industries. In some cases, data are provided by the users of an online service, such as Google maps, in which case they are abundant. But, in industrial applications, experts are traditionally required to provide labeled data, a process that consumes significant amounts of time and money. When it comes to applications associated with human safety, such as drug testing, data collection becomes an even greater concern. Naturally, this problem has not passed unnoticed from the AI community, with researchers looking for ways to get a maximum exploitation of existing data. This practise is termed as data augmentation and can take simple forms, such as applying geometrical transformations on an image, to more sophisticated ones, based on conditional GANs, which are capable of transforming images across different domains and styles.
- Training takes a long time. The larger the repository of labeled data, the longer the training times. The recent hardware acceleration that we experienced facilitated the bloom of deep learning. However, experts have shared concerns that we have over-relied our success to hardware and neglected the learning algorithms themselves. This would not necessarily be bad, if it were not for the alarming deduction of industry experts that Moore’s law, which foresaw an exponential increase in computer power, is no longer on our side.
Although the combination of cyber-physical systems and AI makes for a formidable combination toward automation and advancing quality control, we still have some way to go. A critical observer could comment that we have replaced our need for human intuition with, an easier to satisfy, yet still pressing, need for data. With the next AI discovery being just around the corner, the critical observer cannot be but receptive and vigilant.
 A farewell to AI confusion
A farewell to AI confusion  Future Tech Review #8: Computer vision goes mainstream
Future Tech Review #8: Computer vision goes mainstream 